
[강승우의 머신러닝 이야기] AI의 편견을 만드는 데이터 편향

2016년 호주에에서 공부중인 타이완계 뉴질랜드인 리차드 리(Richard Lee)는 크리스마스를 같이 보내기 위해 뉴질랜드로 돌아가려다, 당혹스러운 상황에 부딪혔다. 온라인 여권 갱신을 위해 업로드한 자신의 사진이 뉴질랜드 정부에 의해 아래와 같은 메시지와 함께 거부되었기 때문이다.
“당신이 업로드하려는 사진은 다음의 이유로 규정에 위배됩니다: 눈을 감았습니다(The photo you want to upload does not meet our criteria because: Subject eyes are closed)”

당시 뉴질랜드 정부는 인공지능을 이용해 여권 사진 심사를 자동화했다. 사진에 대한 거부는 인공지능의 판단 결과였다. 상대적으로 눈이 작은 아시아인의 사진을 인공지능은 인식하지 못했던 것이다.
이후에도 리차드는 분명히 눈을 뜨고 있는 몇몇 사진으로 시도했지만 성공하지 못한다. 리차드는 호주 우체국을 방문해 사진을 찍고 나서야 승인을 받을 수 있었다.
이 사건이 언론에 보도되면서 “인공지능 기술이 인종 차별주의자가 됐다(Technology is getting racist)”는 논란이 일었으나 이는 인공지능에 의한 차별적 결과이기는 하지만, (적어도 아직까지는) 인공지능은 차별적 의도를 가질 수 없다.
인공지능이 만들어 낸 차별적 결과는 인간이 제공한 차별적 데이터에 기반한다.
인공지능에 편견을 심는 데이터 편향
데이터 편향의 대표적인 사례는 1936년 미국 대통령 선거 여론 조사에서 찾아볼 수 있다. 당시 선거에서 공화당 알프레드 랜더(Alfred Randon)와 민주당 프랭클린 루스벨트(Franklin Roosevelt)가 후보로 맞붙었다. 미국 유력 잡지인 ‘리터러리 다이제스트(The Literary Digest)’는 선거 결과에 대한 여론조사를 실시했다.
리터러리 다이제스트는 미국 내 전화가입자와 자동차 소유자 천만명에 대해 질문을 보내고 236만명의 답변을 받았다. 그 결과를 정리해 랜던 57%, 루스벨트는 43%로 랜던의 당선을 예측했다.
1935년에 설립된 갤럽(Gallup)은 당시 신생 기업으로, 리터러리 다이제스트와는 개별적으로 여론조사를 진행했다. 갤럽은 무작위로 선택(Random Sampling)된 1500명에 대해 면접조사를 진행했으며, 이를 정리해 랜던 44%, 루스벨트 56%로, 루스벨트의 승리를 예측했다.

개표 결과는 38% 대 62%로 루스벨트가 당선되면서 갤럽의 예측이 옳았다는 것을 증명할 수 있었다. 236만명을 상대로 1500명으로 승리함으로써, 빅데이터(Big Data)를 상대로 스몰데이터(Small Data)의 유용성을 확인시켰다. 이 승리의 비결은 데이터 편향이었다.
당시 자동차와 전화는 지금처럼 대중적인 제품이 아니었다. 리터러리 다이제스트가 선택한 자동차와 전화 소유자는 대부분 부유한 공화당 지지자였다. 따라서, 리터러리 다이제스트의 예측의 근거가 된 데이터는 공화당에 편향된 데이터였고, 이에 기반한 예측도 공화당에 편향된 예측이 될 수밖에 없었다.
이에 반해 갤럽의 예측은 이런 편향이 없는 데이터를 기반으로 했다. 이 차이가 예측의 결과의 차이를 결정지었다. 이 예측 실패로 당시 대기업이었던 리터러리 다이제스트는 파산하고, 신생기업 갤럽은 대표적인 여론조사 기관으로 성장해 나가기 시작했다.
이 결과는 편향적 데이터 기반의 예측 오류를 보여주는 대표적인 사례로 손꼽히고 있다. 하지만 편향은 ‘추출(sampling)’에서만 생기는 것은 아니다. 판단이 필요한 모든 상황에서 편향에 의한 오류가 발생할 수 있다.
다음 사례는 또 하나의 흥미로운 편향을 보여준다.
2차대전 당시 미군은 전투기의 생존율을 높이기 위해 무사히 귀환한 전투기의 총탄 자국을 연구했다. 그리고, 총탄 자국이 많은 곳의 철판을 강화하기로 했다. 그런데 이는 잘못된 판단이었다.
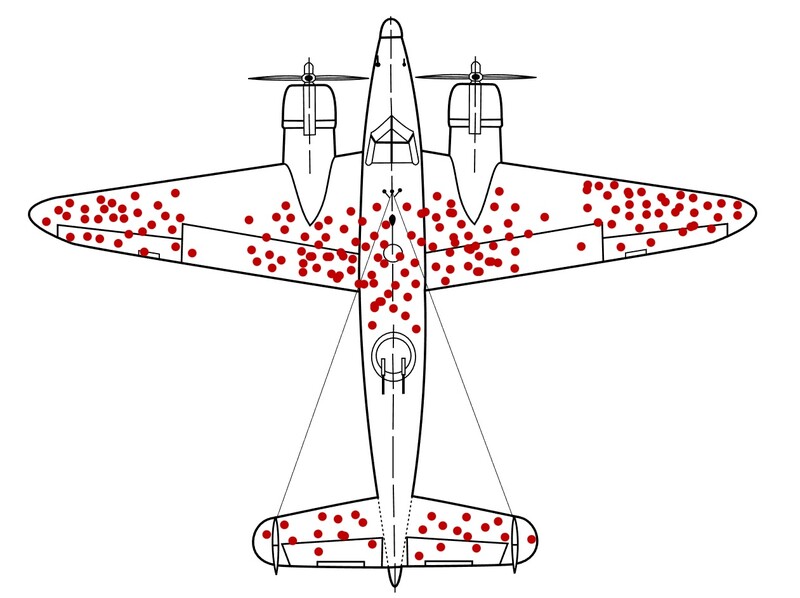
전투 중 비행기의 특정 부위만 총탄에 맞을 확률이 높다고 가정할 수는 없다. 확률적으로는 비행기의 모든 부위가 비슷한 정도 확률로 총탄 피해를 입는다는 가정이 논리적이다. 그렇다면 생환한 비행기가 총탄을 맞은 위치는 비행기에 치명상을 입히지 않는다고 판단해야 한다.
그리고, 돌아오지 못한 비행기가 손상을 입은 곳이 바로 치명적인 손상 부위가 된다. 따라서, 철판을 강화해야 하는 위치는 오히려 생환한 비행기에서 총탄 흔적이 없는 곳이라고 보는 것이 정확하다. 이는 1989년 스티븐 시글러(Stephan Sigler)가 ‘네이처(Nature)’ 5월호에 실은 기사에서 언급된 내용으로 ‘생존 편향(Survivorship Bias)’의 대표적인 사례로 편향적 데이터 선택의 결과를 보여준다.
대표적인 빅테크 기업인 아마존에서도 편향적 데이터 사례를 찾아볼 수 있다. 2018년 10월 아마존은 여성을 차별하는 AI 채용 심사 시스템을 폐기한다고 발표했다. 당시 아마존은 채용 과정에서 이력서 검증을 빠르고 정확하게 진행할 수 있는 AI 시스템을 만들고자 했다. 이력서에 많이 사용되는 5만개의 단어를 인식하는 500개의 모델을 테스트했다.
이를 통해 만들어진 모델을 사용해 100개의 이력서 중, 최상의 5개를 찾았다. 10년 간의 이력서가 훈련 데이터로 사용됐는데, 당시 아마존의 전체 직원의 63%가 남성이었다. 이렇게 편향된 데이터로 훈련된 AI 모델은 남성에 편향된 것으로 판정돼, 2017년 AI 채용 프로젝트는 결국 중단됐다.
미국의 소설가 마크 트웨인은 숫자에 대해 유명한 말을 남겼다. 바로 “숫자는 거짓말하지 않는다. 하지만 거짓말쟁이는 숫자로 거짓말을 한다(Figures don’t lie, but liars figure)”라는 말이다.
그는 지금 이 시대를 살아가고 있다면 인공지능에 대해서도 같은 당부를 했을 것이다. “인공지능기술은 편향적이지 않다. 하지만 편향된 데이터는 인공지능에 편견을 심는다”고 말이다.
필자 강승우 위데이터랩 인공지능연구소장 겸 부사장은 펜타 컴퓨터를 거쳐 BEA, Oracle에서 최고 기술 아키텍트로서 기업의 IT 시스템 문제가 있는 곳의 해결사의 역할을 했다. 글로벌에 통하는 한국 소프트웨어 개발에 대한 열정으로 S전자 AWS 이벤트 로그 분석을 통한 이상징후 탐지, R사의 건축물 균열 탐지 등의 머신러닝 프로젝트를 진행했다. 현재는 딥러닝을 이용한 소프트웨어 취약점 탐지 자동화 연구와 머신러닝과 딥러닝강의를 진행하고 있으며, 비즈니스화에도 노력을 기울이고 있다. 최근 저서로 '머신러닝 배웠으니 활용해볼까요?'가 있다.
'콘텐츠 > 강승우의 머신러닝 이야기' 카테고리의 다른 글
| [강승우의 머신러닝 이야기] 전이학습, 머신 간의 지식 전수 (0) | 2023.02.28 |
|---|---|
| [강승우의 머신러닝 이야기] 진짜보다 진짜같은 가짜 ‘딥페이크’ (0) | 2023.02.28 |
| [강승우의 머신러닝 이야기] 무료 데이터에 대한 독점적 권리는 누구에게 있는가 (0) | 2023.02.28 |
| [강승우의 머신러닝 이야기] 챗GPT는 어떻게 교육받을까? (0) | 2023.02.28 |
| [강승우의 머신러닝 이야기] 어떻게 데이터가 변하니 – 데이터 드리프트(Data Drift) (0) | 2023.02.28 |



