


2020년 우리나라에 국가의 디지털 역량을 강화하기 위한 '디지털 뉴딜 사업'으로 AI Hub가 생긴 것 아시나요?
AI Hub: 인공지능 학습용 데이터를 법국가적으로 모으는 곳

AI 허브는 국내 기업 · 연구소 · 개인 등이 자체적으로 확보하기 어려운 양질의 대용량 인공지능 학습용 데이터들을 공개하고 있는데요,
사람동작 영상 데이터/ 위해물품 엑스레이 이미지 데이터/ 한국어-영어 번역 말뭉치 데이터/ 한국인 안면 이미지 데이터

데이터를 모르는 AI 허브와 같은 사이트의 시초는 UCI 머신러닝 리파지토리입니다. 초기 머신러닝 발전에 기여한 수많은 데이터 셋들이 공개되어 있죠.

UCI 머신러닝 리파지토리는 1987년 UCI 대학원생인 데이비드 아하와 동료들이 만든 데이터 셋 모음 사이트인데요, 이 중 주요 데이터 셋들에대한 비하인드 스토리와 구성을 살펴보도록 하겠습니다.

#와인 품질 데이터 셋
2009년 파울로 코르테즈 외 4명은 데이터를 수집 분석해 와인 맛에 대한 선호도흫 예측할 수 있다는 내용의 논문을 발표했습니다.
" 값싸고 좋은 와인을 마시고 싶었어요,"
「논문 "물리학적 특성으로부터 데이터 마이닐을 통한 와인 선호도 모델링"- 파울로 코르테즈 외 4명」

논문에 쓰인 데이터는 포르투칼 비뉴 베르드 지역에서 만들어진 레드와인 샘플 1599개와 화이트와인 샘플 4899개를 측정한 것입니다.

각 샘플들은 객관적인 속성 11가지와 주관적인 속성인 '품질(맛)'에 대한 데이터를 포함하고 있습니다. 와인 품질(맛)은 0~10으로 평가되었는데, 적어도 3명 이상의 와인 전문가들의 주관적인 의견이 반영되었다고 합니다.
<객관적 수치>
주석산 농도 /아세트산 농도/구연산 농도/잔류 당분 농도/영화 나트륨 농도/유리 이황산 농도/ 밀도/ 수소 이온 농도/ 총 아황산 농도/ 황산칼륨 놀도/ 알코올 도수
<주관적 수치>
와인품질(맛)은 중앙값인 6점
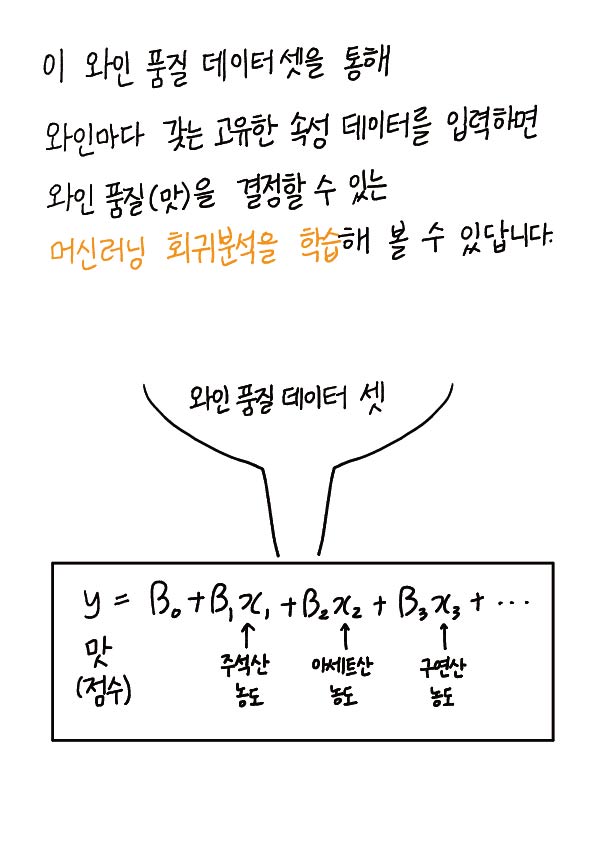
이 와인 품질 데이터셋을 통해 와인마다 갖는 고유한 속성 데이터를 입력하면 와인 품질(맛)을 결정할 수 있는 머신러닝 회귀분석을 학습해 볼 수 있답니다.

#보스턴 집값 데이터 셋
1978년 하버드 도시개발학과 데이비드 해리슨과 다니엘 루빈펠드는 깨끗한 공기가 집값에 큰 영향을 미친다는 연구 결과를 발표했습니다.

그들은 연구결과를 뒷받침하기 위해 환경과 집값의 변동을 보여주는 데이터셋을 만들었습니다. 이름하여 "보스턴 집값 데이터세ㅛ"

이 데이터셋은 보스턴 지역의 주택 506 채에 대한 가격과 이에 영향을 미치는 요소들을 정리한 것입니다. 집값에 영향을 미치는 요소들은 번죄율, 일산화질소 농도 등을 포함해 초 14개 항목으로 나누어져 있습니다.

주어진 환경 요인들과 집값 데이터 분석을 통해 회귀 함수를 만들면, 환경 요인만 보고 집값을 예측할 수 있게 학습시킬 수 있는 것입니다. 보스턴 집값 데이터 셋은 현재 머신러닝의 선형회귀를 테스트하는 가장 유명한 데이터 셋이 되었습니다.

#피마 인디언 당뇨병 데이터 셋 1988년 피마 인디언들의 당뇨병 발생 여부를 예측할 수 있는 방법에 대한 논문이 등장합니다.

피마 인디언은 1950년대까지는 매우 건강한 부족이었는데 미국 정부의 원주민 이주정책으로 사막에서 미국 애리조나 주로 이주 후 전체 인구 중 60%가 당뇨와 비만으로 고통받는 비운의 부족이 되었습니다.

이에 의문을 가진 학자들은 피마 인디언의 건강 상태에 따른 당뇨 발병을 예측하기 위해 데이터를 수집하기 시작했습니다.

그렇게 만들어진 피마 인디언 당뇨병 데이터셋은 576명의 케이스에 대해 각각 8개의 정보와 당뇨병 여부를 추출한 것입니다.

임신횟수+포도당 부하 검사 수치+혈압+팔 삼두근 뒤쪽 피하지방 측정 값+ 혈청 인슐린+체질량지수+당뇨 내력 가중치 값+나이+당뇨병 여부

이 데이터셋에서 당뇨병 여부와 8개 정보들간의 관계 파악을 통해 당뇨 발병을 예측할 수 있는 머신러닝 예측 모델을 만들 수 있습니다.

이렇게 다양한 데이터 셋이 있었기에 머신러닝이 발전할 수 있었답니다. 덕자 여러분들고 평상시에 그냥 지나쳤던 정보들을 하나로 모으고 정리해 보는 게 어떨까료? 우리가 만든 데이터 셋이 인공지능 역사에 한 획을 그을 수고 있지 않을까요?
'위데이터랩 도서 > 야사와 만화로 배우는 인공지능' 카테고리의 다른 글
| [인공지능 만화] 3-18. 추락하던 AMD를 부활시킨 리사 수 (0) | 2021.08.23 |
|---|---|
| [인공지능 만화] 3-17. 이젠 선택이 아닌 필수 GPU의 아버지 젠슨 황 (0) | 2021.08.17 |
| [인공지능 만화]3-15. 빅데이터 시대를 가장 먼저 예견한 비운의 천재 짐 그레이 (0) | 2021.08.03 |
| [인공지능 만화] 3-14. 내 은행 계좌 비밀번호는 어디에 저장되어 있을까? RDBMS (0) | 2021.08.02 |
| [인공지능 만화] 3-13. 오픈소스 DBMS를 대중화시킨 몬티 와이드니어스 (0) | 2021.07.30 |



